発表のポイント:
- 基盤モデルを更新・変更する際に、従来必要であった特化モデルの再学習が不要となる「ポータブルチューニング」技術を確立しました。
- 基盤モデルの出力を調整するための独立したモデルを学習・再利用する、新たな特化学習の枠組みを理論的に導出し、別の基盤モデルにも特化学習の効果を引き継げるようにしました。
- 本技術の活用により、各企業や組織での特化モデルに対する再学習コスト削減だけでなく、再学習させた場合に期待される効果を事前検証するなど幅広い応用が期待できます。
NTT(本社:東京都千代田区、代表取締役社長:島田 明)は、特化型AIの基盤モデル変更に伴う再学習を不要にする新たな学習の仕組みとして「ポータブルチューニング」技術を確立しました。本技術は、基盤モデルの出力を調整する独立したモデルを学習および再利用することで、別の基盤モデルにも学習内容を引き継げるようになり、異なる基盤モデルにおいても追加学習を行うことなく高い特化性能を実現します。本成果は、2025年7月13日から2025年7月19日まで、カナダ・バンクーバーで開催される機械学習分野における最難関国際会議International Conference on Machine Learning (ICML) 2025(*1)において発表されます。
1.背景
近年、高性能かつ多様なAI基盤モデル(以下、基盤モデル)が利用可能となり、様々な企業や組織において生成AIの活用が進んでいます。基盤モデルは一般的なタスクであれば追加学習なしで遂行することもできますが、各組織に特有のタスクやドメインに対して高精度化させるため個別のデータセットでのチューニングを行い、目的に応じた特化モデルとして活用することも一般的となっています。
生成AI活用の長期化に伴い、このような特化モデルの保守コストは無視できない問題となります。特にその元となる基盤モデル側では、知識の最新化やモデル構造の変更などにより定期的に更新されますが、その更新に特化モデルを追随させるためには、基盤モデルを変更する度に再学習が必要となります。学習時は推論時よりも多くの計算リソースを要する上、基盤モデル毎にハイパーパラメータの調整も必要となり、その計算コストや人的コストが課題となってきます。
NTTでは、上記コストを抜本的に削減する新たなアプローチとして、既存の学習結果を様々な基盤モデルに転移させる「学習転移」を提唱し、実際にパラメータの学習過程が基盤モデル間で低コストに転移可能なことを実証しました(*2)。一方でこの学習過程の転移には、以下の2つの課題が残されていました。
・課題① 実用上の高い精度を達成するためには転移後の追加学習が必要である。
・課題② 転移元と転移先でモデル構造が異なる場合に適用できない。
2.研究成果の概要
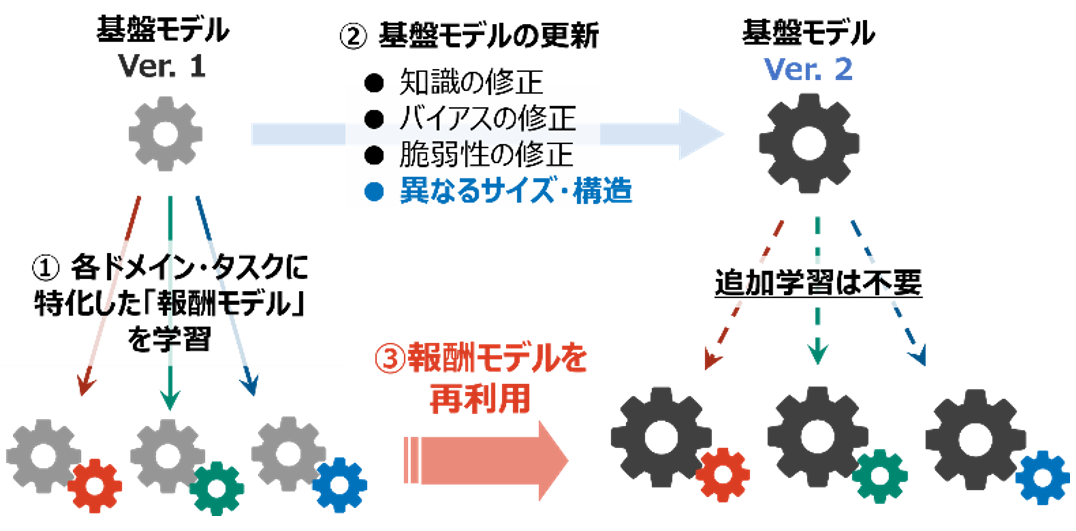
本研究成果では、基盤モデル間で学習結果を転移させる上記「学習転移」技術の実用化に向けて、従来の学習方法を見直し、学習転移に適した新たな学習の枠組みとして「ポータブルチューニング」を導出しました(図1)。従来の方法では基盤モデルのパラメータを直接最適化することで与えられたタスク・ドメインに特化した学習が行われますが、課題①に対して基盤モデルの出力をタスク・ドメイン毎に補正する「報酬モデル」を導入し、その報酬モデルを基盤モデルから独立したモデルとして特化学習を行いました。このような報酬モデルの独立性により、新たな基盤モデルの推論時にも報酬モデルを再利用でき、再学習や追加学習を行うことなく特化学習と同程度の精度を達成することが出来ました。
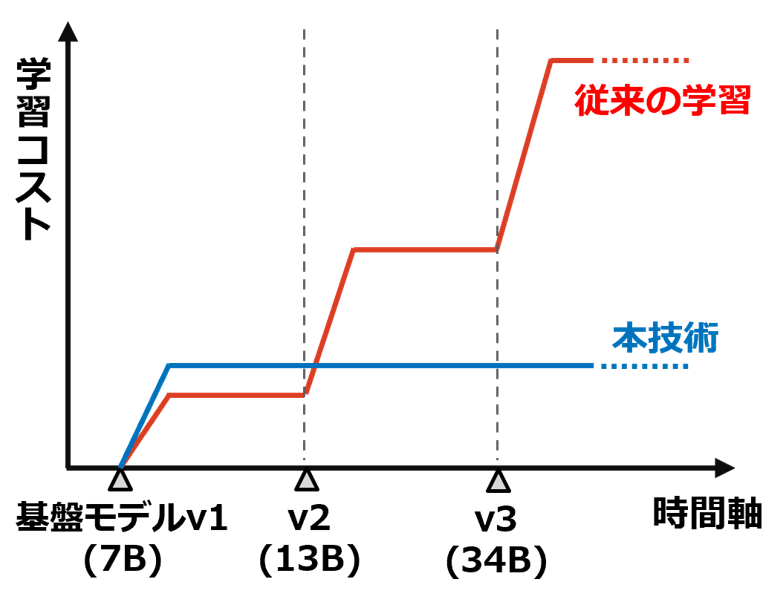
また、課題②に対して、報酬モデルは基盤モデルのモデル構造には依存せず、出力形式(画像分類なら分類ラベル、言語生成ならトークン語彙)にのみ依存するため、転移元と転移先で基盤モデルの構造が異なっていても適用可能です。本技術により、最初の学習時および推論時に報酬モデルの分だけオーバーヘッドが発生するものの、基盤モデルが何度更新されても再学習が不要になるため、学習コストを一定に保つことが可能になりました(図2)。
図 2 本技術によるコスト削減イメージ
3.技術のポイント
ポイント① 報酬学習としての再定式化: 本研究では、まず通常のチューニングが、学習時には暗黙的なタスク報酬(=与えられたタスクに対して、各出力の好ましさを表す値)の学習として、推論時にはその暗黙的なタスク報酬の最大化として再解釈できることに着目しました(図3)。そしてこの解釈に基づくより自然な学習方式として、学習時には暗黙的ではなく直接的に報酬モデルを学習し、推論時にもこの報酬モデルの値を最大化する方向に基盤モデルの出力を補正する、新たな特化学習の枠組みを導出しました。またその学習過程を解析することで、モデル自身からの出力に関する報酬期待値は抑制し、正解データに対する報酬値は大きくする方向に報酬モデルの学習が進むため、本方式が実際に報酬学習として期待される学習を行うことも確認できました。
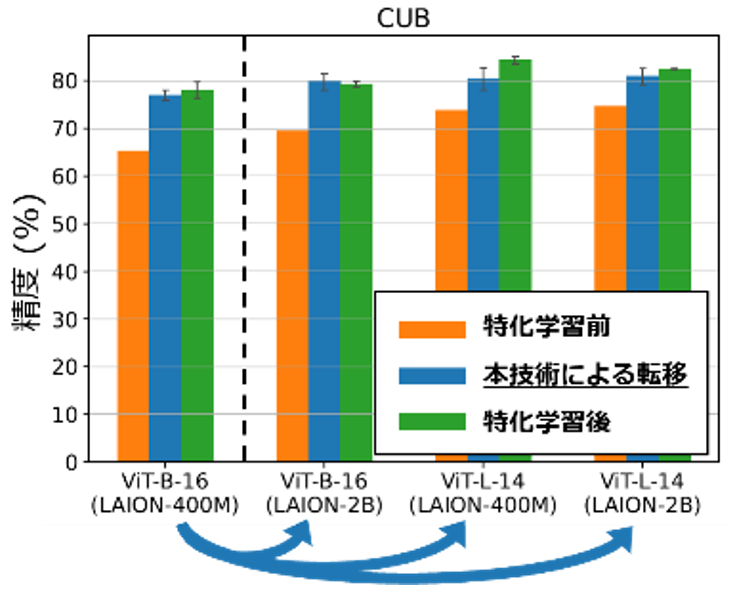
ポイント② 報酬モデルの再利用による学習転移: 本方式では、上記報酬モデルを他の基盤モデルの推論時にも再利用することで、学習時とは異なる基盤モデルに対しても特化学習の効果を与えることが出来ます。実際に理論的にも、基盤モデル間の確率分布としての差が小さいほど学習内容の転移が成功することを保証できるため、最初の学習時および推論時のコストは報酬モデルの分だけやや増えてしまうものの、追加学習を行うことなく精度の高い学習転移が可能となりました。また本方式の学習転移は基盤モデルの出力補正しか行わず、モデル内部の構造には依存しないため、異なるモデル構造間での学習転移が可能となりました。実験においても、画像基盤モデルに対するドメイン毎の特化学習や、言語基盤モデルに対する指示学習の結果を、様々なモデルサイズ・事前学習データをもつ新たな基盤モデルに転移させることで、それぞれの基盤モデルに対して実際に特化学習を行った場合に匹敵する精度を達成することが出来ました。(図4: LAION-400Mデータセット (*3) で事前学習された画像基盤モデルViT-B-16(*4)に対して報酬学習を行い、その報酬を他の基盤モデル(左から二番目以降)に転移させる実験結果。)
図 3 報酬学習としての再定式化
図 4 本技術による転移 (青) と実際の再学習 (緑) の精度比較
4.今後の展開
本技術により、各企業や組織での特化モデルの再学習コスト削減だけでなく、再学習を行った場合に期待される効果を本技術で事前にシミュレーションするといった応用も期待できます。NTTは今後も大規模化するAIのコスト問題解決や多数のAIを連携させるAIコンステレーション (*5) の具現化につながる次世代技術の研究開発に貢献していきます。
発表について:
本成果は、2025年7月13日~19日に開催される機械学習分野における最難関国際会議ICML 2025 (International Conference on Machine Learning) にて、下記のタイトル及び著者で発表されます。
タイトル: “Portable Reward Tuning: Towards Reusable Fine-Tuning across Different Pretrained Models”
著者: 千々和 大輝*、竹内 亨 (コンピュータ&データサイエンス研究所)、長谷川 拓*、西田 京介、齋藤 邦子(人間情報研究所)
*: equal contribution
【用語解説】
※1.ICML 2025
機械学習に関するトップレベルの国際会議。
https://icml.cc/Conferences/2025
※2.2024年5月7日「世界初、AIモデルの再学習コストを大幅に削減可能な過去の学習過程を再利用する「学習転移」を実現」
https://group.ntt/jp/newsrelease/2024/05/07/240507b.html
※3.Schuhmann et al. ”LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs” (2021)
※4.Dosovitskiy et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” (2020)
※5.AIコンステレーション
https://www.rd.ntt/cds/ai-constellation/